If you’ve ever been on call for a production system, you already know how this story starts.
An alert fires. Then another. Slack lights up. Dashboards look fine at first glance, but something is clearly wrong. You jump between logs, metrics, and traces, trying to understand what broke — and why — while the clock keeps ticking.
Even with mature DevOps practices, incident response still feels slow and stressful. Mean Time to Resolution stays high, engineers burn out, and post-incident reviews often surface the same issues again and again.
This is where Large Language Models (LLMs) are starting to make a real difference — not by replacing engineers, but by taking away the most exhausting parts of incident response.
Why Incident Response Still Struggles at Scale
Incident response hasn’t evolved at the same pace as our systems.
Microservices, distributed databases, and frequent deployments have made platforms more powerful — and much harder to reason about during failure.
Some problems show up repeatedly:
- One failure triggers dozens or hundreds of alerts
- Engineers manually scan logs under pressure
- Context is spread across tools, tickets, and chat threads
- Runbooks exist, but they’re outdated or hard to find
- Root cause analysis happens after the damage is done
Rule-based automation helps in known scenarios. But once systems grow complex, static rules simply can’t keep up.
What Makes LLMs Useful During Incidents
Large Language Models are trained to work with messy, unstructured information — exactly the kind of data DevOps teams deal with during incidents.
What matters in practice is not that LLMs “understand language,” but that they can:
- Read and summarize thousands of log lines
- Connect signals across metrics, logs, and past incidents
- Produce explanations that engineers can quickly act on
- Work with natural language instead of brittle rules
Unlike traditional automation, LLMs don’t just look for exact matches. They reason across context, which is critical during real-world failures.
How LLM-Driven Incident Response Differs from Traditional Approaches
In a traditional setup, engineers do most of the thinking:
- Filter alerts manually
- Skim logs line by line
- Write summaries and timelines by hand
With LLM assistance, that workload shifts.
Alert correlation, summarization, and first-pass analysis can happen automatically, while engineers focus on validation and decision-making.
The goal isn’t autonomy. It’s cognitive relief.
Where LLMs Fit into the Incident Lifecycle
LLMs can support incident response at several points:
- Early triage by grouping related alerts
- Summarization of logs and symptoms
- Root cause suggestions based on patterns and history
- Resolution guidance using previous incidents and runbooks
- Post-incident reporting without manual effort
Used correctly, this turns incident response from reactive firefighting into a more structured, calmer process.
A Practical Architecture (Without the Hype)
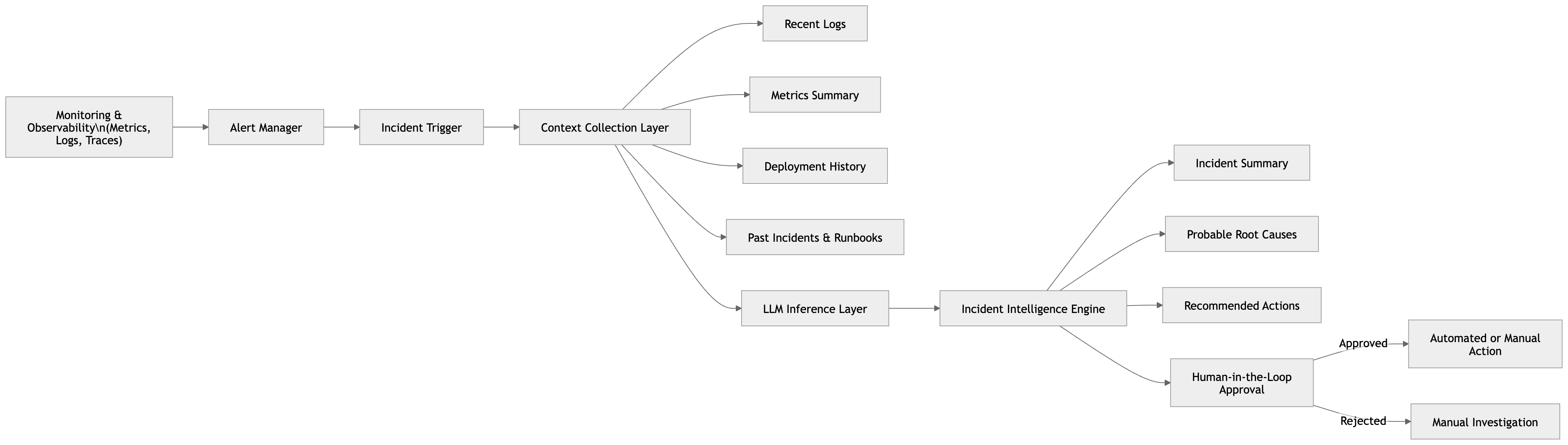
In real systems, LLMs don’t sit alone making decisions.
A typical setup looks like this:
- Monitoring tools trigger alerts
- Logs, metrics, and recent changes are collected
- Historical incidents and runbooks are fetched as context
- The LLM analyzes this combined input
- Recommendations are produced
- A human reviews and decides what to do next
The most important rule here is simple:
LLMs assist. Humans approve.
Where Teams See the Most Immediate Value
Automated Incident Triage
Instead of paging engineers for every alert, LLMs can group related signals into a single incident. This alone can dramatically reduce noise.
Incident Summaries That Actually Help
Rather than dumping raw logs, LLMs produce short explanations that answer the question engineers care about first: what changed and where should I look?
Root Cause Assistance
LLMs don’t magically find the truth, but they can suggest likely causes based on patterns — saving time during investigation.
Living Runbooks
Instead of static documents, runbooks become dynamic suggestions tailored to the current incident.
A Simple Example from Production
Imagine a latency alert in a payment service.
Logs show timeouts across several microservices. The LLM correlates these signals, notices a recent configuration change, and points to a database connection pool limit introduced earlier that day.
The model doesn’t roll anything back automatically.
It presents a summary and recommendation.
An engineer reviews it, confirms the cause, and approves the fix.
Resolution happens in minutes — not because the AI was “smart,” but because it reduced friction.
Tools Matter Less Than Context
Teams often ask which tools are “best” for this.
In practice, the biggest difference comes from how well context is collected and fed into the model, not which LLM or platform you choose.
Bad input leads to bad suggestions — human or AI.
Risks You Should Take Seriously
LLMs are not perfect, and pretending otherwise is dangerous.
Common risks include:
- Confident but incorrect suggestions
- Over-automation without guardrails
- Security issues around sensitive logs
The safest teams start with read-only recommendations, add confidence thresholds, and log every decision for review.
What This Means for the Future of DevOps
LLMs are pushing DevOps toward:
- Faster detection
- Lower MTTR
- Less burnout
- More consistent learning from incidents
They won’t eliminate outages.
But they will change how teams experience them.
When It Makes Sense to Start
LLMs are worth exploring if:
- Incidents are frequent
- Logs are large and noisy
- On-call load is hurting the team
- Downtime has real business impact
Most teams start small — incident summarization is usually the easiest win.
Final Thoughts
LLMs aren’t here to replace DevOps engineers.
They’re here to handle the exhausting parts of incident response — so humans can focus on judgment, experience, and responsibility.
Teams experimenting with LLM-assisted incident response today aren’t chasing hype.
They’re building calmer, more resilient operations for tomorrow.